Architecture
This chapter will navigate you through the architecture of the project.
CERN SIS - Tools & Services uses its general Kubernetes Cluster for the Architecture.
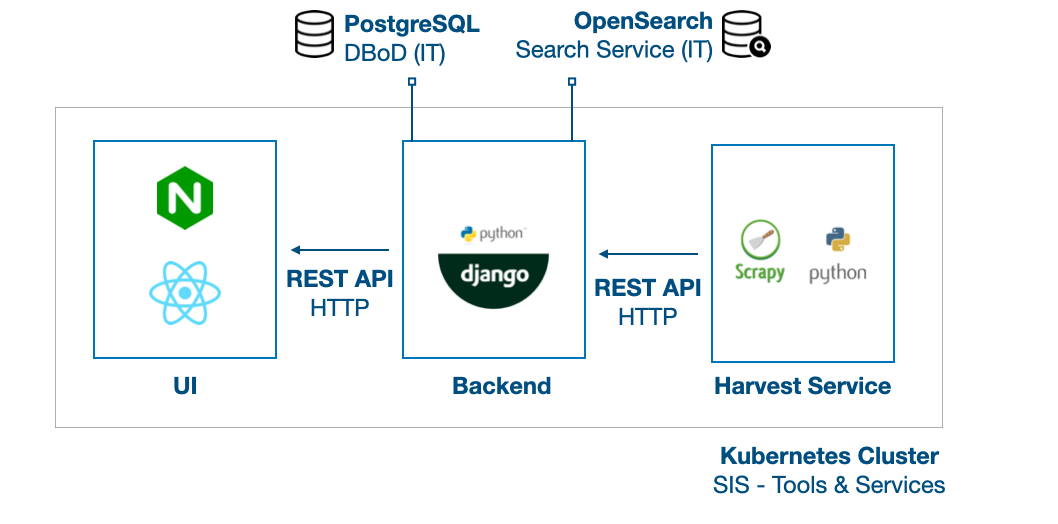
As can be seen above, the whole architecture consists of three main services:
- Harvest Service
- Backend
- User Interface (UI)
Now let's dig in a little bit more, what are the jobs of these services?
Harvest
Initially, the CERN Academic Training lectures are collected from the CERN Document Server (CDS). In order to harvest records from CDS, OAI-PMH mechanism has been used. The already existing harvesting method was reused from INSPIRE which contains already the data transformation from XML to JSON format. When the harvest is successful, the Backend’s REST API is used to create new entries. Then harvesting procedure is running weekly to get the latest records from CDS.
Backend
Built by Django REST Framework with Python.
The lectures that are being harvested from CDS are stored in a PostgreSQL database (DBoD).
On the other hand, there is another service that provides the Search of the website (OpenSearch). This service offer results if lectures are being searched.
Note:
Due to the lack of some important data that were not present previously in CDS, are retrieved from the Indico API (!). We will get back to the reasons and details later.
User Interface (UI)
Built by React.js Single Page Application (SPA) and Node.js.
React manages the frontend part of the project as the role model of its aesthetic design and main provider of the user experience (UX).
Due to the concern of long-term maintenance, the chosen UI Framework has been fallen on Ant Design for using components.
Okay, but how do these services communicate?
The three main services communicate through HTTP requests maintained by REST API that sets in the Backend.