Harvesting
The process of harvesting happens through a mechanism called OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) that in our project is used to translate XML files to JSON format.
How to find metadata of a lecture on CDS?
The fundamental data of an Academic Training lecture record is retrieved from CDS in MARCXML format.
If you go to an Academic Training lecture (EXAMPLE), and you scroll down, you can find links of export environments, including MARCXML.
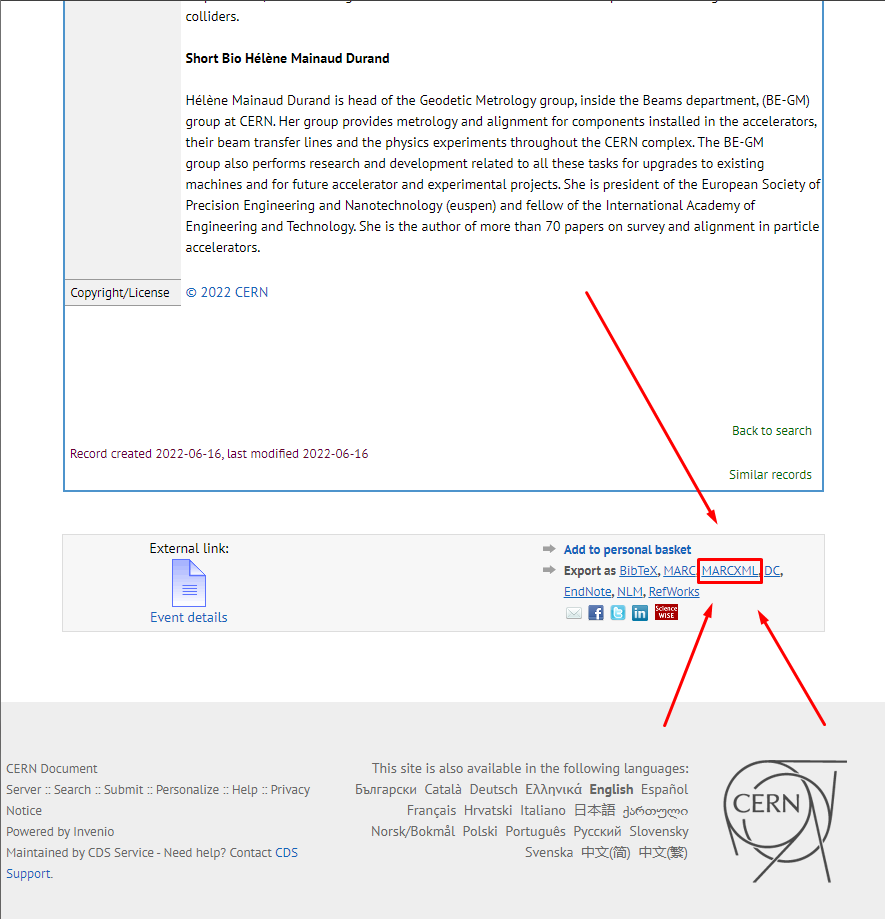
As you open the link of the MARCXML, you find the metadata (EXAMPLE) of the CDS record with MARCXML datafields and tags, as can be seen below.
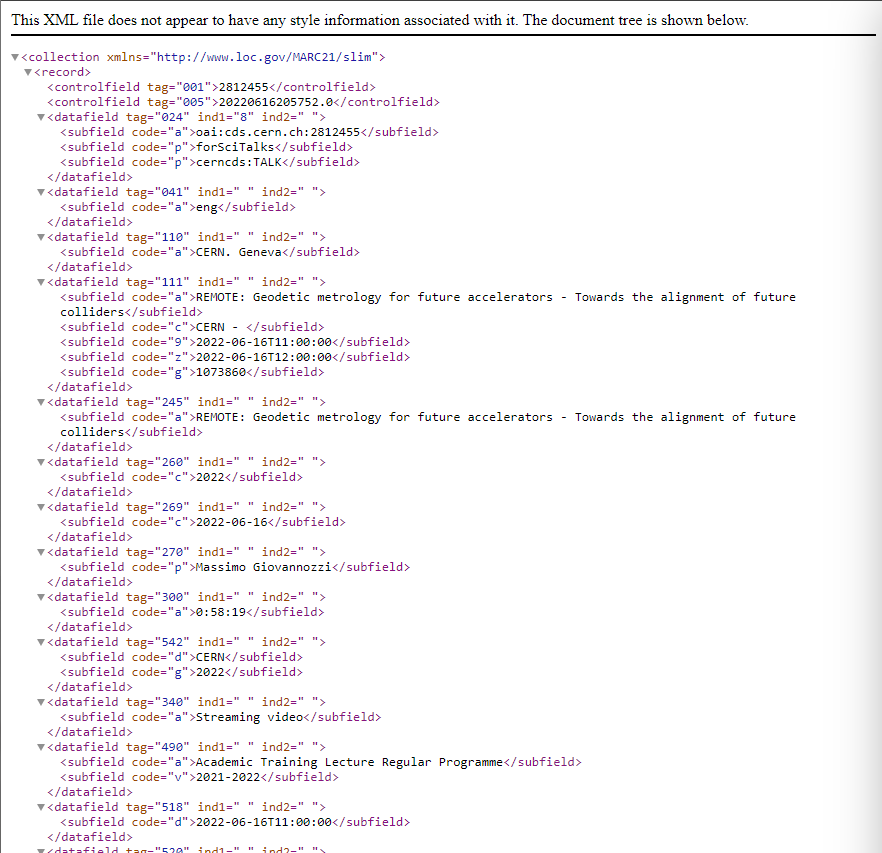
Wonderful, but what do these random numbers next to our data mean? How do they correspond to the tags that we need from CDS?
That is what we will look at now.
OAI-PMH mechanism for MARCXML translation
As you might have discovered, there are some tags with strange numbers in our XML that each of them corresponds to some kind of variable, like the title, speaker, date, etc.
However, we cannot really see or understand them clearly from this metadata. Therefore, we shall take this metadata through a process that translates our XML to a meaningful data that is easily readable. In our case it is transformed to JSON. This process is the OAI-PMH mechanism that was mentioned earlier, and it is going to be described below.
How to find the file where the harvesting happens?
First, a so-called CDS Spider Scrapy file has been implemented that collects the data from CDS. This can be found in /harvest/harvest/spiders/cds_spider.py where the harvesting happens.
How does the CDS Spider collect the data from CDS?
It builds the CDS URL with the query, size and field.
def __build_cds_url(self, query, field=SEARCH_FIELD, size=SIZE):
return CDS_URL.format(query=query, size=size, field=field)
The default URL with these fields included in the variable CDS_URL.
CDS_URL = "https://cds.cern.ch/search?ln=en&cc=Academic+Training+Lectures&action_search=Search&op1=a&m1=a&p1=&f1=&c=Academic+Training+Lectures&c=&sf=&so=d&rm=&rg={size}&sc=0&of=xm&p={query}&f={field}"
It starts requests from CDS:
def start_requests(self):
if self.migrate_all:
self.all_years_gen = self.__gen_all_years
item = next(self.all_years_gen)
url = self.__build_cds_url(item["year"], item["field"])
else:
query = "->".join(self.query)
url = self.__build_cds_url(query)
...
def parse(self, response):
sleep(3)
response.selector.remove_namespaces()
records = response.selector.xpath("//record")
LOGGER.info("Harvested records", count=len(records))
for record in records:
try:
sleep(3)
yield self.parse_item(record, original=record.get())
except Exception as err:
LOGGER.error(err)
Note
LOGGER tracks events that are happenning when our software is running.
It is defined in the beginning of the CDS Spider by LOGGER = structlog.get_logger().
Here, if we want to get all the records from CDS, we do it this way:
try:
if self.migrate_all and (item := next(self.all_years_gen)):
LOGGER.debug("Harvesting next page", year=item["year"])
url = self.__build_cds_url(item["year"], item["field"])
LOGGER.debug("Harvesting url", url=url)
yield Request(url, callback=self.parse)
except StopIteration:
LOGGER.debug("Harvesting all is finished.")
How does the XML-JSON conversion happen?
It takes our XML from CDS and translates it to JSON with matching variables.
For example, let's say we want to take the ID of the lecture which tag from the XML is 001. It will be assigned to a new record called lecture_id this way:
def parse_item(self, selector, original=None):
...
record["lecture_id"] = selector.xpath(".//controlfield[@tag=001]/text()").get()
OR
Another example for abstract with the tag 520:
record["abstract"] = selector.xpath(
'.//datafield[@tag=520]/subfield[@code="a"]/text()'
).get()
Now here's where the data is passed to create new record. But first, note that these libraries must be imported:
from dojson.contrib.marc21.utils import create_record
from inspire_dojson.cds import cds2hep_marc
INSPIRE already has a method that transforms data from MARCXML to JSON and vice-versa (INSPIRE-DoJSON). This has been reused here.
Last but not least, this part takes the original record and creates a new one by converting the XML record to JSON.
data = cds2hep_marc.do(create_record(original))
...
return record
When the harvest shows a successful response, the Backend’s REST API is used to create new entries.
Note
The harvesting procedure is running weekly to get the latest records from CDS.